









You’ve probably seen it.
You generate a perfect AI character — the lighting, expression, and style all feel right — then try to recreate them in a new scene, and suddenly they look… different.
The hair shifts shade. The nose changes shape. The style drifts.
That’s because visual consistency is still one of the hardest unsolved problems in AI art.
It’s what separates a one-off image from a coherent story. And even as diffusion and video models evolve fast, none of them truly remember what they just made.
Why AI “forgets”
Most image and video generators — whether Midjourney, Runway, or Kling — create each frame or photo from scratch.
They don’t actually recall previous outputs.
A 2024 report from Stanford’s AI Visual Systems Lab described it clearly:
“Current diffusion systems are generative, not referential — they recreate visual tokens anew rather than persisting an entity or style.”
So if you prompt:
“A woman with brown hair sitting in a car,”
and then write:
“The same woman steps out of the car,”
the model has no real notion of “the same woman.” It’s reinterpreting your words from zero every time.
That’s why your character’s identity — face, outfit, lighting — drifts. Not because AI is bad at art, but because it lacks continuity.
Real-world examples of drift
This issue is everywhere once you start looking:
- Midjourney V6 added character reference images — yet even with anchors, results vary with angle or style changes.
- Runway Gen-3 Alpha maintains background continuity, but faces subtly morph over long clips.
- Kling 2.5 delivers cinematic realism, but not consistent identity — a person can age, slim, or transform mid-scene.
- Even Sora, OpenAI’s most advanced video model, shows frame-by-frame variations in emotion and proportion.
For creators trying to build narrative videos or branded content, this becomes a major obstacle.
What works right now
Until persistent identity models mature, two workflows make a real difference:
1. Start from a single image
Begin your generation with one strong reference image of your character or subject — and keep reusing that image across every new scene or shot.
That gives the model a fixed anchor, reducing the randomness of facial and stylistic interpretation.
2. Extend video using video-to-video
If you already have a short video — for example, a clip of your character in a car — you can upload it as the input for your next generation.
The model builds on existing visuals rather than starting from text alone, making it easier to preserve pose, light, and identity.
Neither approach is perfect, but together they’re the current best practice across professional workflows in Runway, Pika, and Wondercraft.
The future: creative memory and continuity
The next leap forward will come from persistent visual memory — systems that can recall entities and maintain them across sessions and models.
This evolution is already visible:
- Google Veo 3 can reuse latent representations between shots for smoother transitions.
- Pika 1.5 and Runway Gen-3 are testing internal identity embeddings to track faces over time.
- ByteDance’s OmniHuman-1.5 combines reasoning models with diffusion transformers to retain emotional and visual coherence across long sequences.
In short, AI is learning to remember.
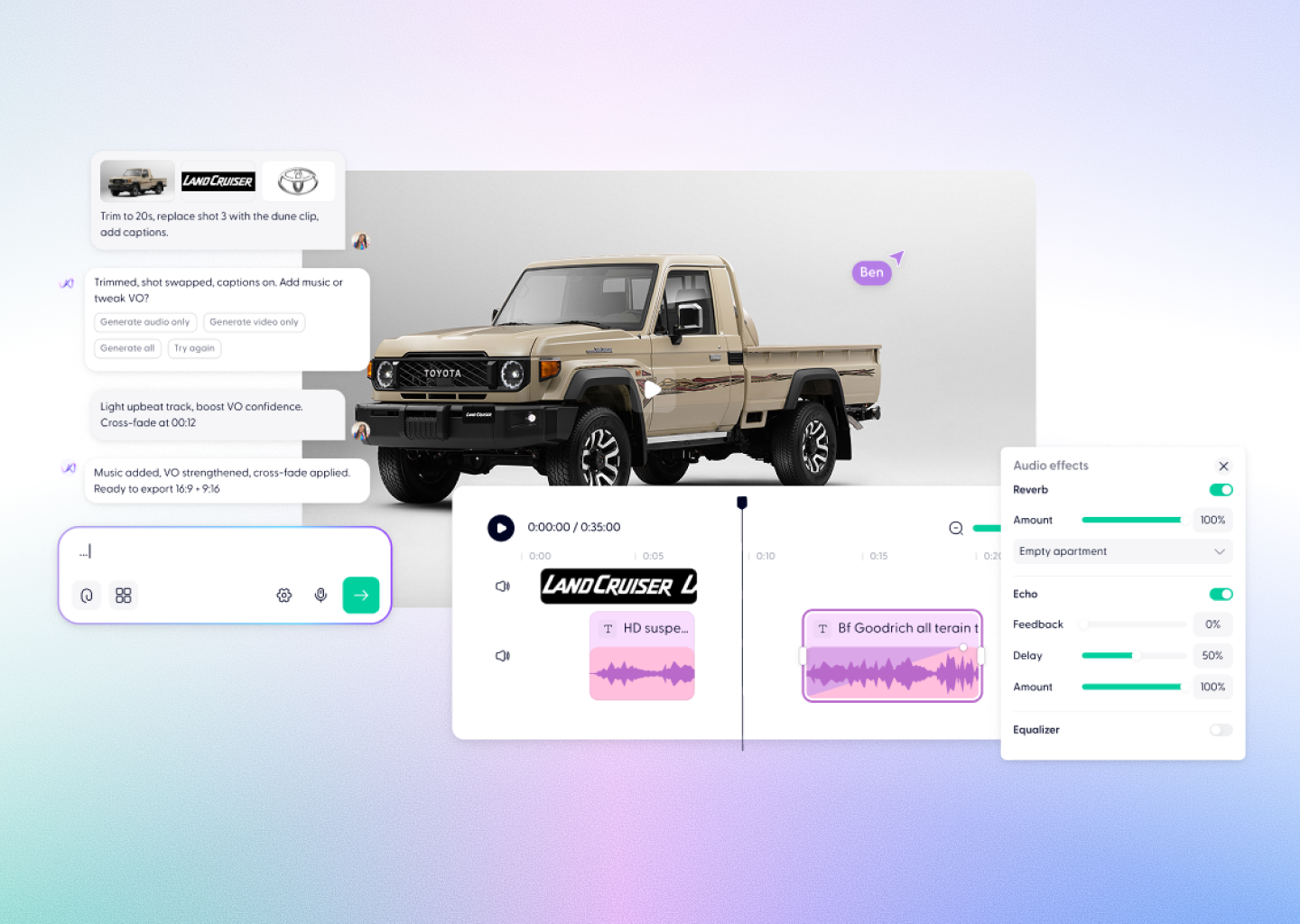
How Wondercraft is approaching it
Inside Wondercraft Studio, Wonda — the AI creative director — already applies basic semantic memory when generating multiple scenes.
When you start a project with an uploaded image, Wonda uses that visual reference across your storyboard, helping keep character and lighting consistent throughout a sequence.
Soon, that workflow will expand beyond storyboards.
You’ll be able to:
- Upload a single image or clip once
- Create multiple scenes from it
- Keep the same person, product, or background throughout
And in the future, Wonda will automatically detect when you’re working with a recurring subject and maintain continuity intelligently — without you having to re-upload or describe it again.
That’s how real creative direction works: not generation, but evolution.
Why consistency matters more than realism
Visual perfection gets attention — but consistency builds recognition.
Whether it’s a YouTube personality, a digital trainer, or a brand mascot, the power of a recurring image lies in familiarity. If your visuals keep changing, audiences lose connection.
That’s why Wondercraft’s long-term focus isn’t just better generation — it’s continuity across media.
Because when visuals, voices, and tone stay aligned, creators can finally build entire narratives with AI instead of isolated clips.
Try it in Wondercraft Studio: Upload a reference image, start a storyboard, and let Wonda carry your character, lighting, and feel across every generation.
AI shouldn’t reinvent your story every time — it should help you continue it.


